
好吧,说点实在的。
上周,我与一位创始人通了一次电话,他花了 4 个月的时间构建自定义租户配置。
在这 4 个月里,他的客户得到了什么? 什么也没得到。没有任何新功能。当他们埋头于 kubernetes yaml 和 terraform 配置时,产品却停滞不前。
他告诉我 "我们以为要三个星期"。
无人问津的钱坑
让我们快速计算一下,因为我想大多数人都不会真正坐下来计算。
高级工程师的平均工资:假设为 15 万美元/年。
从零开始建立租户供应:至少需要 8-12 周时间(这还算宽松)。
两名工程师工作 10 周,仅工资一项就达 14.4 万美元。
这只是为了让第 1 版正常工作。
每个星期都要花 10-20 个小时来维持正常运转。SSL 证书在凌晨 2 点过期,容器濒临破产,卷积被填满,DNS 因有人更改配置而中断。
仅维修人工费一项,每年就要多出**37,000 - 75,000 美元。
同时,对于整个平台来说,ShipCrew 的成本还不到一名工程师的月薪。
数学对 DIY 来说不起作用。
停止建设基础设施,开始运输会发生什么?
我一直想说的是,那些停止建设自己的基础设施的球队才是公布收入数字的球队。
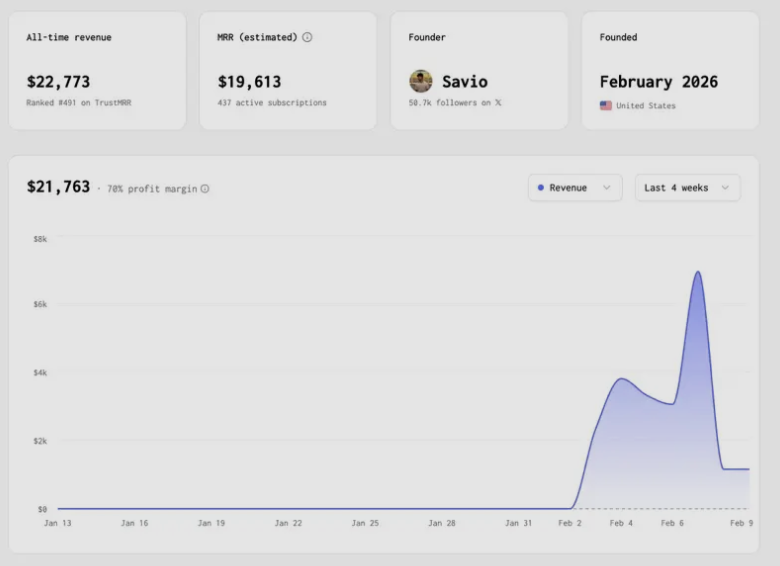
Savio 通过 437 个活跃订阅获得了 19,613 美元的 MRR。他并不是通过手工滚动容器编排实现这一目标的。他是通过每周交付功能,同时由平台处理无聊的事情实现的。
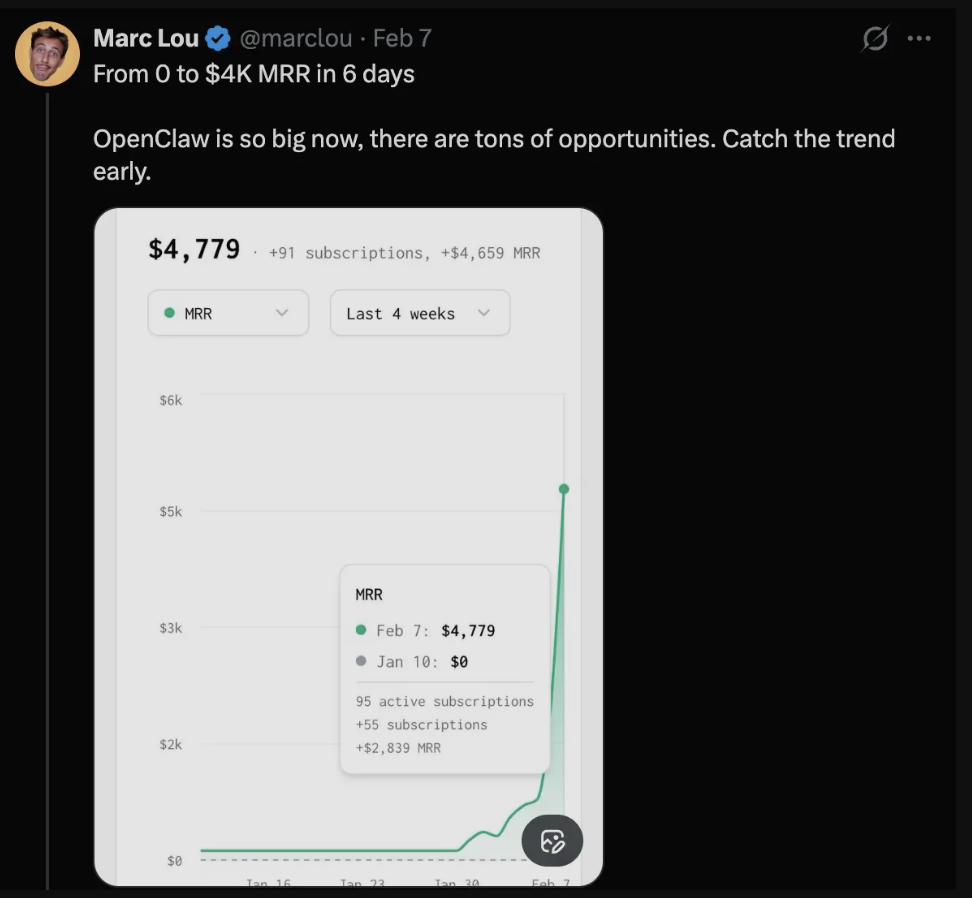
6 天内,Marc Lou 的 MRR 从 0 美元增至 4,779 美元。95 个有效订阅。六天。当其他团队还在调试他们的配置脚本时,他已经开始收取收入了。
这些都不是假设,而是真人的真实仪表盘,他们做出了一个简单的决定:不要再把工程时间花在不能使产品与众不同的基础架构上了。
"但我们需要控制"
我经常听到这样的话"我们需要完全控制我们的基础设施"
好吧,但是......你觉得呢?
他们不需要 Kubernetes,他们需要的是交付功能和达成交易。
你知道客户真正关心的是什么吗? 你的人工智能是否有效、是否快速、他们的数据是否安全。从来没有人因为SaaS的基础架构是手工制作的而购买它。
现在取得胜利的团队都是那些几个月前就把无聊的基础架构工作外包出去的团队。他们每周都会推出新功能,而他们的竞争对手却在调试 nginx 配置。
我反复看到的是
在过去的几个月里,我大概和 40-50 个团队谈过话:
- 团队决定打造多租户人工智能产品
- 团队从共享运行时开始(方便快捷)
- 第一个企业潜在客户询问隔离问题
- 团队惊慌失措,开始构建自定义配置
- 3 个月消失
- 团队终于有所收获,但仍很脆弱
- 团队永远都在维护它,而不是运送它
每次都是如此。
那些跳过第 4-7 步的团队? 当其他人还在与开发人员搏斗时,是他们在完成企业交易。
凌晨三点坏掉的东西
我见过 DIY 配置出错的真实情况:
- SSL 证书在周六晚上过期。由于设置证书的工程师休假,花了 6 个小时才修好。
- 一个租户将容量填充到 100%,但监控系统没有发现。
- 迁移后的 dns 传播问题。半数租户在 4 个小时内无法到达运行时间
- 容器内存泄漏,性能缓慢数周才有人注意到。
- 错误的 API 密钥被注入到错误的租户中。
每一个都是来自真实团队的真实故事。每一个都是平台为您处理时不会发生的事情。
复利问题
让我不解的不仅仅是直接费用。
每花一个月在基础设施上,就等于少花一个月:
- 可完成企业交易的功能
- 改进入职服务,减少客户流失
- 可打开新市场的整合
- 客户付费购买的实际人工智能产品
外包基础架构的团队与没有外包基础架构的团队之间的差距每个月都在拉大。
6 个月后,使用 ShipCrew 的团队发布了 20 项功能,而 DIY 团队发布了 8 项功能,并且仍在修补他们的供应系统。
这可不是一点点差别,而是完全不同的轨迹。
"下个季度再做"
下一季度永远不会到来,总有理由拖延。
你每拖延一个季度,就等于又拖延了一个季度:
- 烧掉的工程时间
- 因无法证明隔离而失去企业交易
- 削弱客户信任的事件
- 没有建成的功能
改用 ShipCrew 的团队并不是因为他们想改用,而是因为他们在进行数字运算后发现 DIY 方法阻碍了他们的发展。
听着,我并不是说它适合所有人
如果你有一个专门的平台团队,无事可做,那就自己构建。如果基础架构就是你的产品,那就自己构建。如果你的平台成本确实高于构建成本,那就自己构建。
但如果你是一个由 2-10 名工程师组成的团队,正试图推出一款人工智能产品,那么在租户配置上花费几个月的时间可能是最浪费时间的事情。
15 分钟与 4 个月相比,我不知道如何计算得更清楚。
最坏的情况是你损失了 15 分钟,最好的情况是你恢复了 3 个月的生活。