
我就实话实说吧
当我们刚开始构建人工智能产品时,我们认为共享运行时很好。一个大容器,所有客户使用同一个端点。轻而易举。周五发货,之后喝啤酒。
我们大错特错了。
前 10 位顾客?一切都很美好
您进行部署。客户注册。API 响应迅速。日志干净整洁。你感觉自己是个天才。
你告诉你的联合创始人 "看,我就说我们不需要 kubernetes"。击掌。生活多美好
然后客户 11 加入。他们有一个你意想不到的用例。他们每分钟发送 400 个请求。其他 10 个客户呢?他们现在都出现了超时。你的闲置系统正在爆炸。
但这没问题,对吗?只需添加速率限制。快速解决方案。
错了这只是个开始。
50 位客户的实际故障情况
让我带你回顾一下发生在我们身上的事情,因为我真希望以前有人告诉过我这些。
*** 我们有一个共享运行时,env 中包含所有客户 API 密钥。一个糟糕的错误处理程序将全部 env 记录到我们的监控工具中。我们三个星期都没有注意到。客户的机密在 Datadog 中保存了三个星期。我至今还为此失眠。
***客户 34 发现他们可以发送提示,让模型输出无限代币。运行时间 OOM'd。50 个客户全部宕机。时间是周二凌晨 2:47。问我怎么知道的?
*** 客户 A 在 200 毫秒内获得响应。而客户 B 的相同请求则需要 4 秒钟。为什么?因为客户 C 正在运行一个批处理任务,占用了所有 CPU。你甚至无法在共享运行时调试,因为每个人的流量都混在一起。
*** 企业客户想要 GPT-4。另一个想要 Claude。第三个客户需要自定义系统提示。在共享运行时?祝你好运。你基本上需要为基础架构添加功能标志。这根本不可能。
没人做的数学
下面是我希望在开始之前计算出的结果:
构建共享运行时间的成本: 2 周
东西损坏后,将 50 个客户迁移到隔离运行时的成本: 3 个月
因为跨租户数据泄漏而失去 2 个企业客户的代价: 无价(而且不是好的方面)
迁移过程非常艰难。我们必须建立一个调配系统、容器协调、容量管理、DNS 路由、SSL 证书和环境隔离。同时还要保证 50 个客户的运行。这就像在飞机飞行途中更换引擎。
与此同时,从孤立无援开始的人们正在打造真正的产品
当我们沉浸在迁移工作中时,其他团队从第一天起就在独立的运行环境下推出了实际产品:
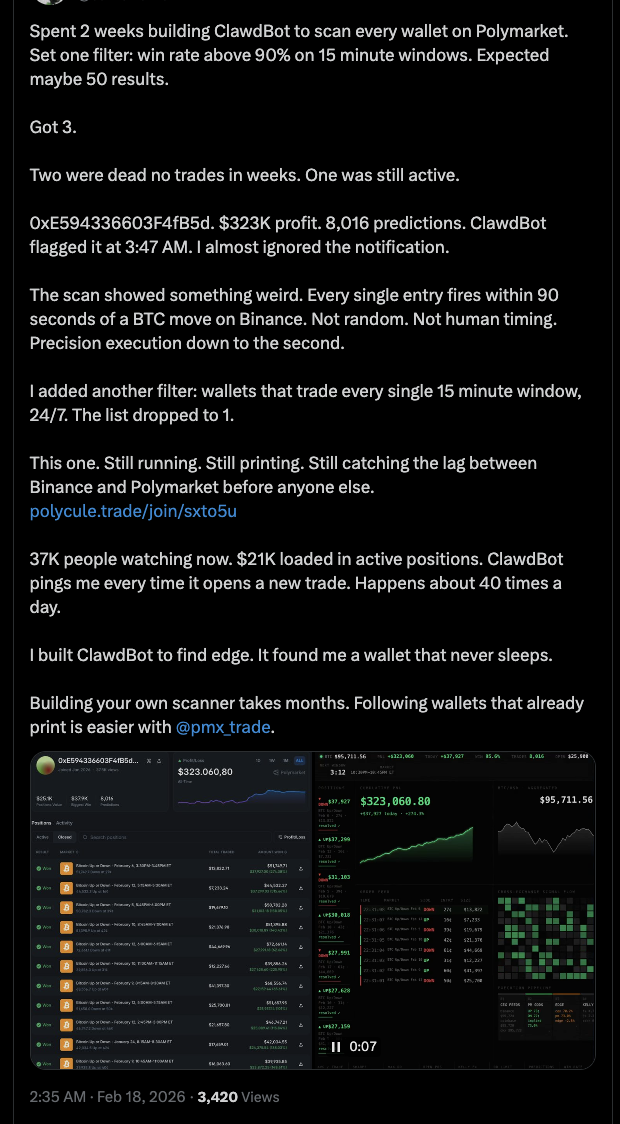
ClawField 基于隔离运行时间建立了实时交易机器人扫描仪。每个输入都在 30 秒内完成,执行精确到秒。他不是在调试跨租户问题。他是在构建能赚钱的功能。
Max Blade 推出了一整套 iOS 应用程序,可以启动隔离的 OpenClaw 代理。无需 Telegram,无需 API 密钥,无需设置。只需登录,你的代理就可以上线了。他之所以创建该应用程序,是因为他不想被困在维护共享基础设施的环境中。
这些都是来自真正的建筑商的真实产品。他们从隔离开始,这样就可以把时间花在产品上,而不是管道上。
为什么在为时已晚之前没有人进行转换
我与很多开发人工智能产品的创始人交谈过。他们都说了同样的话:
"等顾客多了,我们再隔离"
这就是陷阱。当你有足够多的客户证明隔离是合理的时候,你也有太多的客户无法安全地迁移。转换容易吗?就是现在。在你遇到问题之前。
就像备份一样。在丢失数据之前,没人会关心备份。然后突然间,备份就成了世界上最重要的事情。
按租户隔离的实际效果
我们花了 3 个月的时间进行迁移,结果是这样的:
- 每个客户都有自己的 Docker 容器
- 每个容器在
/data都有自己的持久卷。 - 每个租户的环境变量完全独立
- 每个客户都会得到一个独一无二的 URL,如
customer.agents.shipclaw.io - 一个客户崩溃不会影响其他人
- 您可以自定义每个客户的型号、配置和费率限制
两者之间的差别可谓天壤之别。支持单下降了 80%。不再有凌晨 3 点的页面。企业客户不再威胁要离开。
"但隔离运行时间很昂贵
这是我听到最多的反对意见。更多的集装箱 = 更多的钱,对吗?
算是吧。但让我们来真正算一算:
共享运行时间成本:
- 基础设施:每月 200 美元
- 凌晨 3 点事件响应:你的理智
- 因可靠性问题造成的客户流失:每月损失 5k+ 美元的收入
- 因为 "我们不能保证隔离 "而失去企业交易:???
- 调试跨租户问题的工程时间:20 小时/周
隔离运行时间:
- 基础设施:400 美元/月(是的,更多)
- 凌晨 3 点事件:基本为零
- 客户流失率:大幅下降
- 企业交易:您现在可以真正达成交易
- 处理基础设施问题的工程时间:2 小时/周
基础设施成本更高。其他费用则低得多。净成本?你会领先很多。
我们现在是如何利用 ShipClaw 的
在经历了所有这些痛苦之后,我们建立了 ShipClaw,这样其他人就不必这样做了。
打开可视化生成器。在画布上拖动一个运行时节点。连接一个用于路由的网关。添加用于持久存储的卷。添加用于保密的 Env Config。点击部署。
就是这样。每个客户都能获得完全独立的 OpenClaw 运行时。拥有自己的容器、卷、环境变量和 URL。您无需编写任何 Dockerfile 或 Kubernetes 清单。
我们花了 3 个月时间手动构建的整个系统?现在可以拖拽部署了。
我给你免费建议的部分
听着,如果你正在为多个客户构建人工智能产品,请从第一天起就开始隔离。我不管你是使用 ShipClaw 还是自己构建,或者完全使用其他东西。只要不共享运行时就行。
技术债务会迅速增加。安全风险是真实存在的。凌晨 3 点的页面会出现。而后期迁移要比正确开始难 10 倍。
相信我。我用昂贵的方式学到了这些,所以你不必这样做。